Removing Control Flow Flattening with Binary Ninja
If you've been reversing for a while then eventually you'll come up against a control flow graph that looks like this:
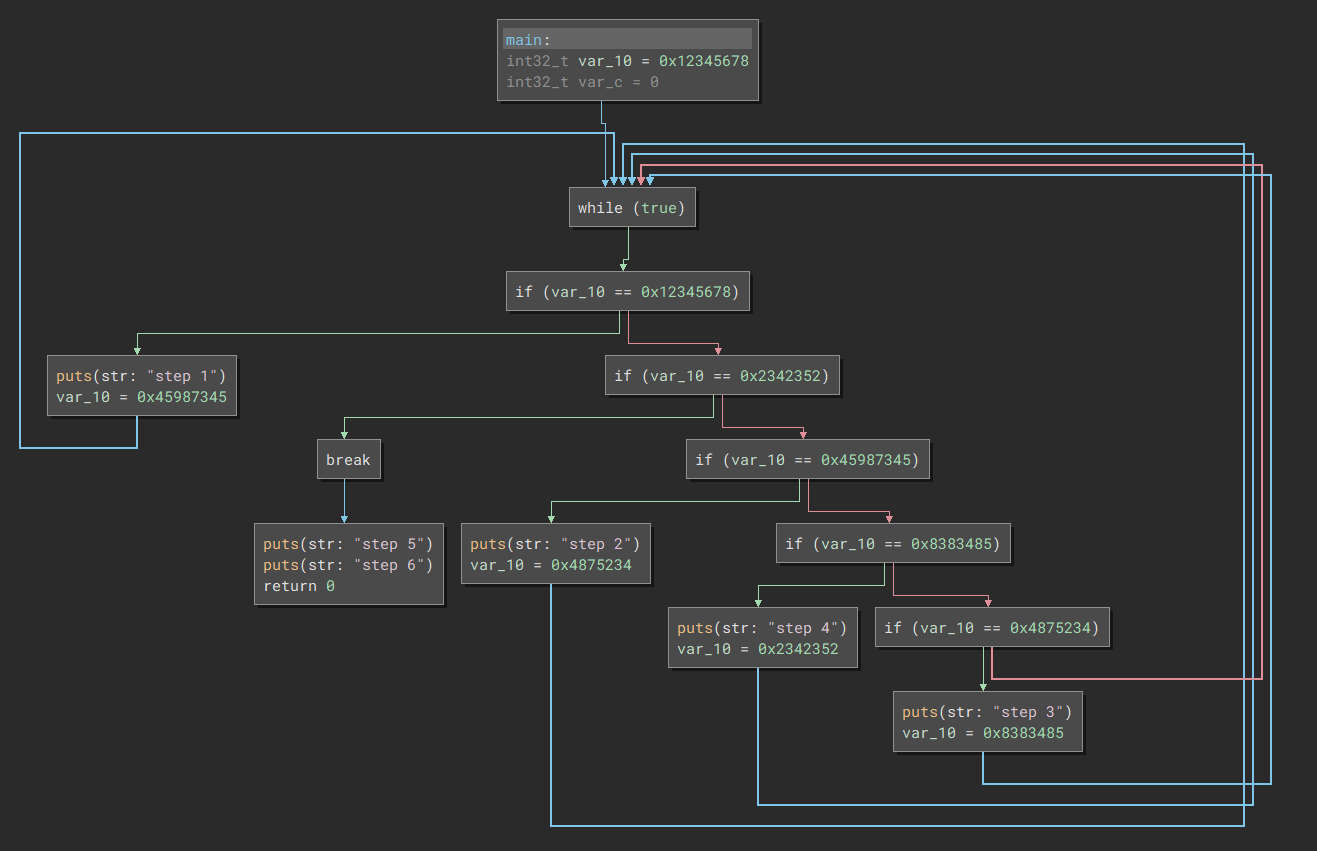
This is a simple toy app hosted at https://github.com/samrussell/cff_playground if you feel like following along at home. The plugin isn't complete yet but I'll include all the snippets, you can copypaste them as you go through and it'll magically convert this tangled mess into a much more obvious app.
Theory (and practice?)
If you're new to handling control flow flattening then definitely take a look at Tim Blazytko's article and obfuscation detection plugin to get your head around the theory. The short version is we're looking for two things:
Dominators are blocks that are always hit before another block. If A is always hit before B, then A dominates B. A block always dominates itself by the way.
Loops are when we go from block A and end up back at the start of block A
Incoming edges are the links from blocks that execute before our block - if A can jump to B then we say B has an incoming edge from A
With these concepts in mind, we are going to look for the following:
Find a block that has at least 3 incoming edges from blocks that it dominates
Or in Python (you can just paste this into the Binary Ninja Python console)
func = bv.get_function_at(here) # make sure your cursor is at the start of the function
cff_heads = []
for block in func.hlil.basic_blocks:
dominated_edges = sum([(1 if block in x.source.dominators else 0) for x in block.incoming_edges])
if dominated_edges >= 3:
cff_heads.append(block)
If we do this right then cff_heads will have one block, and that is the start of our while loop. We then want to find all the blocks that are part of this. One way to do it would be to use Binary Ninja's Abstract Syntax Tree (AST) interface, but I found this is good for traversing the decompiled HLIL, it was hard to link it back to the basic blocks and the graph interface. The way I did this was to start from the top, and traverse backwards through all incoming edges that are dominated by our first block:
cffhead = cff_heads[0] # only one head in this example
blocks = set()
to_visit = [cffhead]
while len(to_visit):
block = to_visit.pop()
for edge in block.incoming_edges:
candidate_block = edge.source
if cffhead in candidate_block.dominators and candidate_block not in blocks:
blocks.add(candidate_block)
to_visit.append(candidate_block)
blocks = sorted(blocks)
We now have a blocks variable that contains all the blocks in our flattened function:

Find the key
One common pattern for control flow flattening has a single variable that gets set to a number that corresponds to the next piece of code to jump to. We're going to scan through all the IF statements to see if there's one variable that sticks out more than the others:
blocks_to_visit = [x for x in blocks]
conditions = set()
while len(blocks_to_visit):
block = blocks_to_visit.pop()
for edge in block.incoming_edges:
condition = func.hlil[edge.source.end-1]
if isinstance(condition, HighLevelILIf):
conditions.add(condition)

We can eyeball this and say "yeah it's var_10, duh", and the way we do this in Python is to count the number of times each variable is referenced, and take the most popular one (the one referenced the most times):
varcounts = defaultdict(lambda: 0)
for condition in conditions:
for var in condition.condition.vars:
varcounts[var] += 1
varcounts = dict(varcounts)
target_var = max(varcounts.items(), key=lambda x: x[1])[0]
var_conditions = list(filter(lambda x: target_var in x.condition.vars, conditions))

The var_conditions filter isn't super necessary for this example, but for more complex examples it will be necessary to strip out any other IF statements that we aren't using.
We're going to make a wild assumption here that every single IF statement checking var_10 is part of the dispatcher, and it's true here, but it won't be true for every sample.
Pairing up
The way var_10 is used looks like this:
Check
var_10against value1If equal then jump to path1
Execute
Set
var_10to value2...
We need to find all the values that var_10 gets set to, find out where they get set, and find out which piece of code they correspond to. Once we've done that we can convert them to direct jumps and cut out the middleman (the dispatcher) and then Binary Ninja can work its magic and give us some nice normal code.
code_lookup = {}
# look over all the IF statements
for condition in var_conditions:
# we're only dealing with `if var_10 == 0x1234`
if not isinstance(condition.condition, HighLevelILCmpE):
raise Exception("Can't handle %s type %s" % (condition.condition, type(condition.condition)))
# get the true branch
true_branches = list(filter(lambda x: x.type == BranchType.TrueBranch, condition.il_basic_block.outgoing_edges))
if len(true_branches) != 1:
raise Exception("Got %d true branches on %s ?!" % (len(true_branches), condition.il_basic_block.outgoing_edges))
true_branch = true_branches[0]
# get the const value
consts = list(filter(lambda x: isinstance(x, HighLevelILConst), condition.condition.operands))
if len(consts) != 1:
raise Exception("Got %d consts in %s" % (len(consts), condition.condition))
code_lookup[consts[0].value] = true_branch.target

We now have a mapping for where each code points; for example 0x2342352 goes to block x86_64@0x7-0x8 . The next step is to look at where var_10 gets set and map all of these together:
block_exits = {}
for block in blocks:
# in every block
instructions = [func.hlil[x] for x in range(block.start, block.end)]
# look at every instruction
for instruction in instructions:
if isinstance(instruction, HighLevelILAssign) and instruction.operands[0].var == target_var:
# if var_10 is set anywhere in this block then consider this an exit block
block_exits[instruction.operands[1].value] = block

This part of the code makes another wild assumption that var_10 only gets set in the last block before going back to the dispatcher. This is enough for now, but in more complex CFF examples we will need to look a bit deeper.
In any case now we can see for example that code 0x2342352 gets set at the end of block x86_64@0xc-0xe . We then want the end of block x86_64@0xc-0xe to jump directly to x86_64@0x7-0x8 (from earlier).
Putting it all together

I'm gonna dump a bunch of code here so you have it in one place, then we'll break it apart and I'll explain what's happening:
for code, block in block_exits.items():
asmblock = func.get_basic_block_at(func.hlil[block.start].address)
lastinstruction = asmblock.disassembly_text[-1]
if lastinstruction.tokens[0].text != "jmp":
raise Exception("Couldn't patch %s, doesn't end with jmp but %s" % (block, lastinstruction.tokens))
address = lastinstruction.address
length = asmblock.end - address
print("0x%X Patch at %x, %d bytes" % (code.value, address, length))
outblock = code_lookup[code]
if outblock.get_disassembly_text()[0].tokens[0].text == "break":
outblock = outblock.outgoing_edges[0].target
outasmblock = func.get_basic_block_at(func.hlil[outblock.start].address)
out_address = outasmblock.start
print("Change jump to go to %x" % out_address)
bytecode = bv.read(address, length)
if length == 2:
if bytecode[0] != 0xeb:
print("Didn't recognise JMP opcode %02X, skipping" % bytecode[0])
continue
delta = out_address - asmblock.end
if abs(delta) > 0x7f:
print("Delta for short jump is 0x%02X, cannot do short jump, skipping" % abs(delta))
continue
if delta < 0:
delta += 0x100
newbytecode = struct.pack("<BB", 0xeb, delta)
elif length == 5:
if bytecode[0] != 0xe9:
print("Didn't recognise JMP opcode %02X, skipping" % bytecode[0])
continue
delta = out_address - asmblock.end
if delta < 0:
delta += 0x100
delta += 0xFFFFFF00
newbytecode = struct.pack("<BL", 0xe9, delta)
else:
print("JMP length wrong %d, skipping" % length)
continue
print("Replacing jump %s with %s" % (bytecode.hex(), newbytecode.hex()))
bv.write(address, newbytecode)
For starters, we'll loop over all the blocks where var_10 gets set, and make sure they end with a jmp opcode:
for code, block in block_exits.items():
# converting between hlil and asm isn't pretty
asmblock = func.get_basic_block_at(func.hlil[block.start].address)
# disassembly_text gives us the disasm lines, so we want the last one
lastinstruction = asmblock.disassembly_text[-1]
if lastinstruction.tokens[0].text != "jmp":
raise Exception("Couldn't patch %s, doesn't end with jmp but %s" % (block, lastinstruction.tokens))
# block.end is the start of the next block
# so block.end - instruction.address tells us how long the instruction is
address = lastinstruction.address
length = asmblock.end - address
print("0x%X Patch at %x, %d bytes" % (code.value, address, length))
We then find the corresponding IF statement and see where that jumps to for the same code number:
outblock = code_lookup[code]
# break commands are weird in HLIL
# they end up pointing at the JNE opcode so we need to skip forward
if outblock.get_disassembly_text()[0].tokens[0].text == "break":
# get next block
outblock = outblock.outgoing_edges[0].target
# as above, convert from HLIL block to asm block
outasmblock = func.get_basic_block_at(func.hlil[outblock.start].address)
# we jump to the start of this block so start address is easy here
out_address = outasmblock.start
print("Change jump to go to %x" % out_address)
This is the fun (and processor-dependent) part, writing the patch. In my example gcc has just used short and near jumps so this is all I'm handling (https://www.felixcloutier.com/x86/jmp.html if you get stuck). We read in the JMP instruction, check which sort it is, make sure we have enough bytes to rewrite the jump, and then build our own bytecode:
bytecode = bv.read(address, length)
# handle short jump
if length == 2:
if bytecode[0] != 0xeb:
print("Didn't recognise JMP opcode %02X, skipping" % bytecode[0])
continue
# calculate distance
delta = out_address - asmblock.end
# short jump can only go 0x7f forward or 0x80 back
if abs(delta) > 0x7f:
print("Delta for short jump is 0x%02X, cannot do short jump, skipping" % abs(delta))
continue
# convert delta
# e.g. -8 should go to 0xf8
if delta < 0:
delta += 0x100
# build the new bytecode
newbytecode = struct.pack("<BB", 0xeb, delta)
The version for the near jump is basically the same
elif length == 5:
if bytecode[0] != 0xe9:
print("Didn't recognise JMP opcode %02X, skipping" % bytecode[0])
continue
# calculate distance
delta = out_address - asmblock.end
# don't need to check length it's 32 bit
# convert delta
if delta < 0:
delta += 0x100
delta += 0xFFFFFF00
newbytecode = struct.pack("<BL", 0xe9, delta)
else:
print("JMP length wrong %d, skipping" % length)
continue
And then we write our new bytecode:
print("Replacing jump %s with %s" % (bytecode.hex(), newbytecode.hex()))
bv.write(address, newbytecode)
And like magic, our big scary CFF state machine turns into this harmless little function:
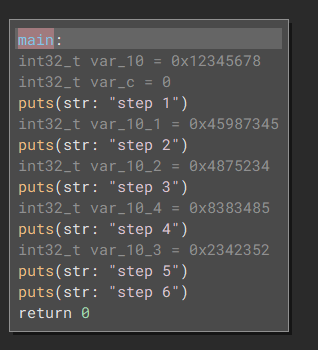
Next steps
There are a lot of caveats here, but the main one is this:
- This is a toy app that handles the simplest CFF case
You'll have to extend it if you want to do anything more complicated and use it in the real world. I hope you enjoyed this though, and I hope you find a way to use it in your day to day reversing.
Addendum
Jordan from the Binary Ninja team made a couple of points around converting between HLIL and other representations:
There are no guarantees the blocks line up as you'd expect.
You can use
hlil.llilsto get the list of LLIL instructions that make up a HLIL instruction. These are not guaranteed to be in order, but something likemin(x.address for x in func.hlil[6].llils)might be a better way to get the start address vs my approach of jumping between HLIL and disassembly blocks. This is an exercise for the reader :)