Control Flow Flattening: How to build your own
I was really really excited when Open Obfuscator was launched. I've enjoyed the challenges that application obfuscation have given us over the years, and it was fun to find a well documented and open source obfuscator that we could play with and try to break, while also finding ways to improve our toolkits and extend them to other protection tools.
I recently did some work on removing control flattening with Binary Ninja, using a basic handcrafted sample, and the next step was to build my own obfuscator and then build the scripts to reverse it, and so on, and so on. Here's the next step in that journey.
Step 1: Making an LLVM pass
Most of the credit goes to Open Obfuscator here. You need to create a shared library that exports this function:
extern "C" __attribute__((visibility("default"))) LLVM_ATTRIBUTE_WEAK ::llvm::PassPluginLibraryInfo
llvmGetPassPluginInfo() {
return getPassPluginInfo();
}
This getPassPluginInfo() function is going to look something like this:
PassPluginLibraryInfo getPassPluginInfo() {
static std::atomic<bool> ONCE_FLAG(false);
return {LLVM_PLUGIN_API_VERSION, "obfs", "0.0.1",
[](PassBuilder &PB) {
try {
PB.registerPipelineEarlySimplificationEPCallback(
[&] (ModulePassManager &MPM, OptimizationLevel opt) {
if (ONCE_FLAG) {
return true;
}
MPM.addPass(obfs::ControlFlowFlattening());
ONCE_FLAG = true;
return true;
}
);
} catch (const std::exception& e) {
outs() << "Error: " << e.what() << "\n";
}
}};
};
There are variations of this, this one comes from Open Obfuscator and it does everything we need it to. There are variations floating around on StackOverflow saying you can use a FunctionPassManager but that doesn't work without enabling optimisations in clang (-O1 etc) whereas this does. If there's one thing I've learned about LLVM it's not to ask too many questions.
The function we jump to is going to accept an llvm::Module object, and we just need to iterate over this to get our llvm::Function objects, and then we're done with the boilerplate:
struct ControlFlowFlattening : public PassInfoMixin<ControlFlowFlattening> {
PreservedAnalyses run(Module &M, ModuleAnalysisManager &MAM) {
for (Function& F : M) {
flattenFunction(F);
}
return PreservedAnalyses::none();
}
};
Step 2: Working with LLVM Functions
The LLVM documentation is very, very extensive, and it's all open source, so you can browse the Function documentation to your heart's content. The cool thing here is we can just iterate over it and it will give us llvm::BasicBlock objects. A BasicBlock is a set of instructions that will run together, and it ends with something like a branch or a return. BasicBlocks can branch to other BasicBlocks. What we want to do is find where the BasicBlocks connect to each other, and add some logic so that the branch always gets followed, but it takes a path that isn't obvious to the decompiler. Take this code for example:
void simple_branch(int value){
printf("Before branch\n");
if(value > 5) {
printf("value > 5\n");
}
else{
printf("value <= 5\n");
}
printf("After branch\n");
}
We can compile this and print out the LLVM and see it's split into 4 BasicBlocks:
New basic block %1
Instruction: %2 = alloca i32, align 4
Instruction: store i32 %0, i32* %2, align 4
Instruction: %3 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([15 x i8], [15 x i8]* @.str.6, i64 0, i64 0))
Instruction: %4 = load i32, i32* %2, align 4
Instruction: %5 = icmp sgt i32 %4, 5
Instruction: br i1 %5, label %6, label %8
New basic block %6
Instruction: %7 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([11 x i8], [11 x i8]* @.str.7, i64 0, i64 0))
Instruction: br label %10
New basic block %8
Instruction: %9 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([12 x i8], [12 x i8]* @.str.8, i64 0, i64 0))
Instruction: br label %10
New basic block %10
Instruction: %11 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([14 x i8], [14 x i8]* @.str.9, i64 0, i64 0))
Instruction: ret void
Or decompile it in Binary Ninja:
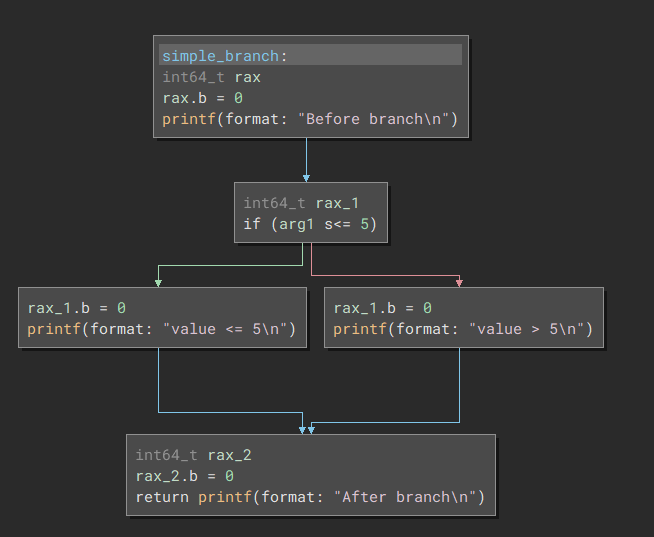
Note that Binary Ninja adds an extra block; this isn't important right now so imagine we just have 4. If the code just did some calculations and some calls and returned it would only need a single BasicBlock, but once we add an if statement we need to branch... and when we branch we create new BasicBlocks to hold this code. At the end of the if and else statements they jump back to the same place, so this becomes our fourth and final BasicBlock for this function.
Step 3: Building a dispatch block
We want to route all of our logic through a single block, so that instead of a nice tree that a reverse engineer can follow, we end up with a mess of lines everywhere and make it less obvious what the shape of the function looks like. This can be anywhere we want, I've decided to put mine right at the start of the function. We'll make the first block jump to our dispatcher and then jump to the rest of the blocks directly from there.
What if the first block branches to multiple places?
We can steal the branch off the end of the first block and put it in its own block after the dispatcher. We can implement this ourselves (create new block, add branch to this, copy across branch into the bottom of the new block), but LLVM actually gives us a helper function which makes this super easy.
BasicBlock &entryBlockTail = F.getEntryBlock();
BasicBlock* pNewEntryBlock = entryBlockTail.splitBasicBlockBefore(entryBlockTail.getTerminator(), "");
Once we've split off our stub, we know the first block has an unconditional branch at the end, and we can insert our block in-between - we make save the Successor from the terminating branch, then make this branch point at our dispatcher block, and then add a branch instruction to the dispatcher, and we're all plugged in.
// Get the EntryBlock and the one after it - the Successor
BasicBlock &EntryBlock = F.getEntryBlock();
auto* br = dyn_cast<BranchInst>(EntryBlock.getTerminator());
BasicBlock *Successor = br->getSuccessor(0);
// we create DispatchBlock and plug it in at both ends
// DispatchBlock -> Successor
BasicBlock* DispatchBlock = BasicBlock::Create(F.getContext(), "dispatch_block", &F);
IRBuilder<> DispatchBuilder(DispatchBlock, DispatchBlock->begin());
DispatchBuilder.CreateBr(Successor);
// EntryBlock -> DispatchBlock
br->setSuccessor(0, DispatchBlock);
DispatchBlock->moveAfter(&EntryBlock);
Step 4: Routing blocks via the dispatcher
There are two parts to this:
Setting the dispatch variable and jumping to the dispatcher
Checking the dispatch variable and deciding from there where to go
Setting the dispatch variable
We're often looking at conditional branches so we'll loop over each successor and do the same:
Create a new detour block to jump to
Make the detour block set the dispatch variable
Jump to the dispatch block
for (unsigned i = 0; i < br->getNumSuccessors(); ++i) {
// we start with block -> successor
BasicBlock *Successor = br->getSuccessor(i);
// create detour block
// DispatchVar = X
// jmp DispatchBlock
BasicBlock *DetourBlock = BasicBlock::Create(F.getContext(), "", &F);
IRBuilder<> Builder(DetourBlock);
Builder.CreateStore(ConstantInt::get(Builder.getInt32Ty(), ++dispatchVal), DispatchVar);
Builder.CreateBr(DispatchBlock);
// insert block after our current one
// block -> DetourBlock
br->setSuccessor(i, DetourBlock);
DetourBlock->moveAfter(block);
}
Adding the branch in the dispatch block
This is a little tricky because each branch is going to look like this:
Load dispatch var
Compare dispatch var (this is a
cmpor similar on x86)Branch based off the result of the comparison
You may note that these are separate instructions, so we can't just insert before the last one. I did try this by mistake and the results were hilarious but also left me with a useless app. In hindsight we could just add another block in the chain, but since everything is already jumping to the dispatch block we can also use another cool LLVM helper function: SplitBlockAndInsertIfThen() . This means we end up inserting each comparison at the start of the dispatch block, but it means the code required is as simple as this:
// if (DispatchVar == dispatchVal) goto successor;
Instruction* FirstInst = DispatchBlock->getFirstNonPHI();
IRBuilder<> DispatchBuilder(FirstInst);
LoadInst* loadSwitchVar = DispatchBuilder.CreateLoad(DispatchBuilder.getInt32Ty(), DispatchVar, "dispatch_var");
auto *Cond = DispatchBuilder.CreateICmpEQ(ConstantInt::get(DispatchBuilder.getInt32Ty(), dispatchVal), loadSwitchVar);
SplitBlockAndInsertIfThen(Cond, FirstInst, false, nullptr, (DomTreeUpdater *)nullptr, nullptr, Successor);
We can probably optimise this and start the dispatch block with the dispatch variable load and always branch one instruction after the start, but this also works (and there's nothing to stop us doing an optimisation pass after this).
Step 5: Admire the results
Remember our simple code from earlier?
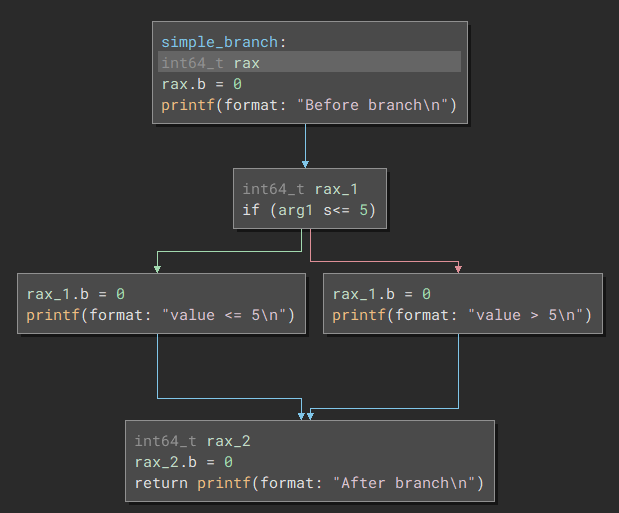
If we compile it with our new LLVM pass it looks like this:
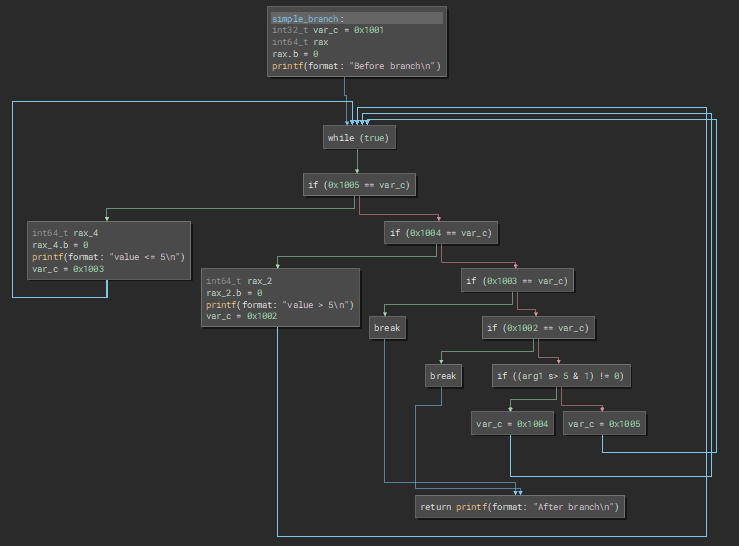
This isn't terrible, but let's take a slightly bigger function:
void obfuscate_me(int number){
printf("Checking how big the number is\n");
int counter = 1;
if(number < 5) {
printf("number < 5\n");
counter++;
}
else {
printf("number >= 5\n");
counter+= 2;
}
printf("Some divisors\n");
if(number % 3) {
printf("number %% 3\n");
counter++;
}
if(number % 5) {
printf("number %% 5\n");
counter++;
}
}
This would normally compile into this:
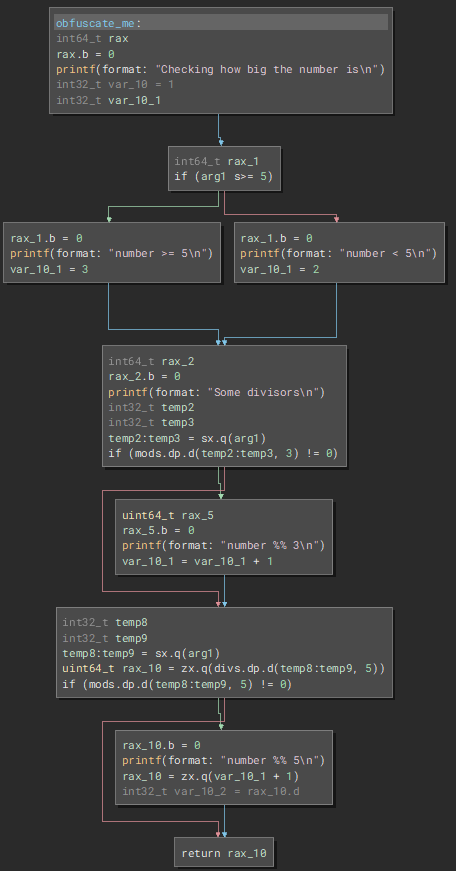
But when we flatten it we get this:
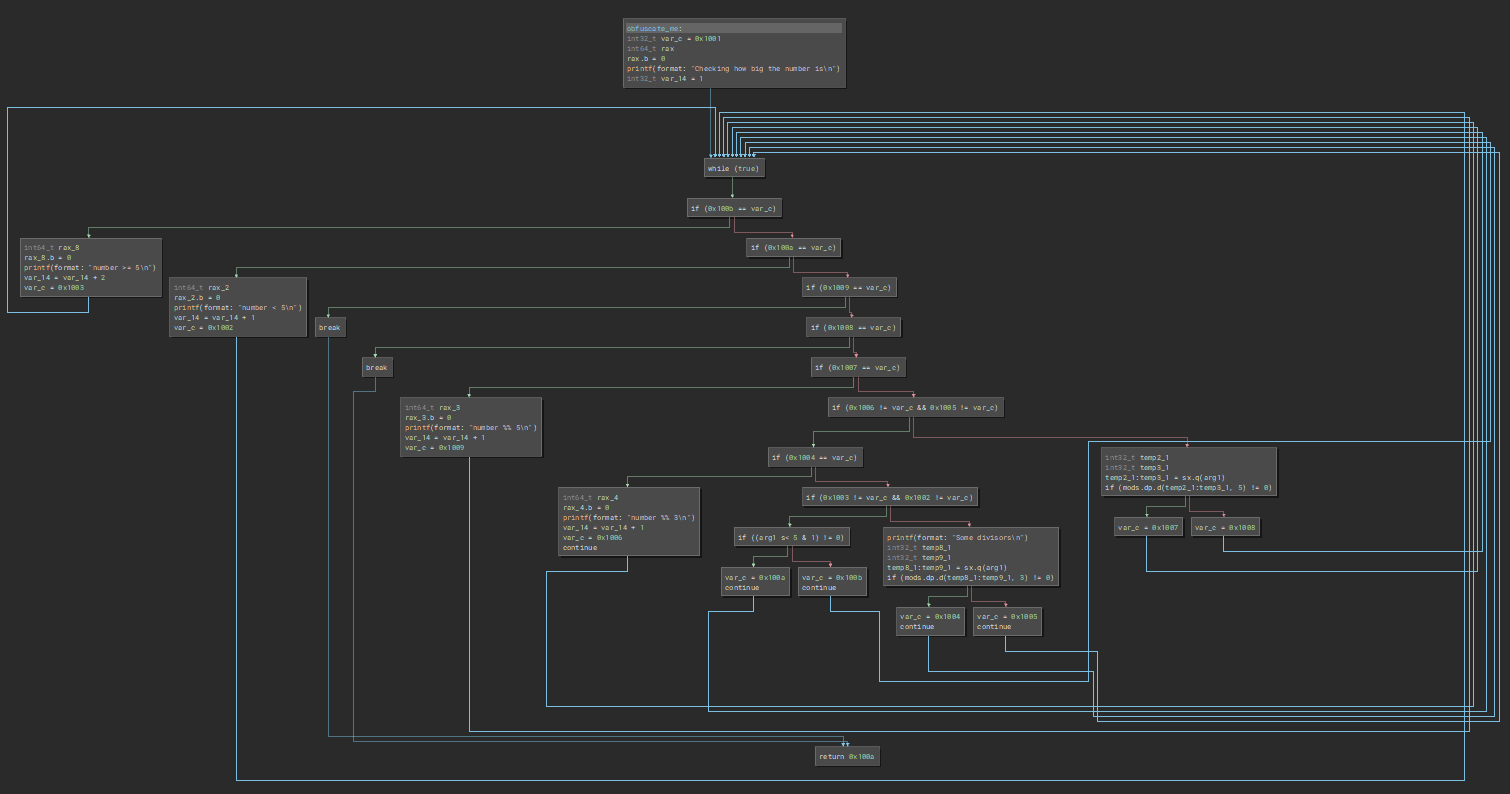
And as you can imagine, a bigger function would be even more confusing once we flatten it. We can further muddy the waters by adding MBA fake conditional branches with fake unreachable code and add that into the mix, and the function steadily becomes more difficult to work with when reversing.
Conclusion
I hope you all enjoyed this, this is a toy proof of concept project and it implements a bare minimum of cases (it will break on block terminators that aren't simple branches, for example), but you could also apply this to an app right now and it would add a thin layer of security on top. This isn't an LLVM tutorial so I'm not going to go into detail there, but feel free to use this as a base if you always wanted to play with LLVM and didn't know where to start.
Code is here: https://github.com/samrussell/obfus
Thanks again to Romain Thomas as I've leaned heavily on O-MVLL for the original idea and for tips when I've gotten stuck with the code.
Next step is obviously to extend my script from last time and see what it takes to turn this back into something readable, stay tuned or feel free to give it a try yourself.