Lifting VM based obfuscators in Binary Ninja
Building a Binary Ninja architecture plugin to reverse a software protection challenge
Carrying on from the previous article, we can take the first of the tigress challenges and finesse it so the VM parser shows up nicely as a big switch/case statement and we can unpick what all the VM handlers do. The next step is to translate the VM handlers into some intermediate language (IL), lift the code, and then apply optimisations to hopefully leave us with some simple and readable code. Binary Ninja gives us the ability to write our own plugins to help with this, so let's go through how we went from a partially-reversed obfuscator VM to some readable code.
If you want to skip this and just want the plugin then check out https://github.com/samrussell/tigress_disasm
Reversing the VM handlers
I like to do this by going through the bytecode and reversing one command at a time. The bytecode is at 602060 so let's start there and we find the first byte is 0x60. If we look through our handler_entry table we find that 0x60 points to 4008e9 and we can click through to the handler:
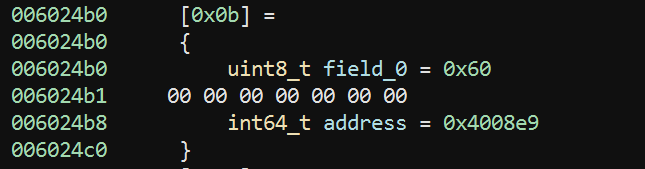
If we look in the High Level IL view we can see the code laid out as follows:
*(vstack + 8) = *(vip + 1)
vstack = vstack + 8
vip = &vip[9]
continue
This handler does the following:
- Reads the next 8 bytes from
VIPas a QWORD and puts them on the stack - Advances the stack pointer by 8 bytes (or 1 QWORD)
- Advances
VIPby 9 bytes (1 byte for the opcode + 8 bytes for the immediate value)
So this pushes a QWORD immediate onto the stack, and we'll call this opcode loadq
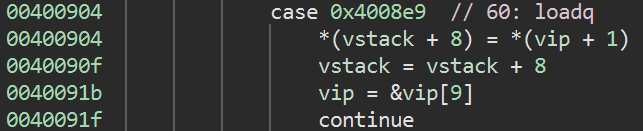
Our first command is thus 60 08 00 00 00 00 00 00 00, or loadq 8 and our second command is the same opcode, 60 00 00 00 00 00 00 00 00, or loadq 0.
The next byte is 0x4e, so we'll jump to the handler at 40088d:
vip = &vip[1]
*vstack = *vstack
continue
This handler does the following:
- Advances
VIPby one byte - Takes a QWORD from the stack and puts it back in place
Operations like these can sometimes be hiding something sneaky that the disassembler will ignore, but it appears this is exactly what is happening if we look at the disassembly:
mov rax, qword [rbp-0x70 {vip}] // put VIP in RAX
add rax, 0x1 // increment RAX
mov qword [rbp-0x70 {vip}], rax // put RAX back in VIP
// vip = vip + 1
mov rax, qword [rbp-0x80 {vstack}] // put vstack in RAX
mov rdx, qword [rbp-0x80 {vstack}] // put vstack in RDX
mov rdx, qword [rdx] // RDX = *vstack
mov qword [rax], rdx // *vstack = RDX
// *vstack = *vstack
jmp 0x40070d
This will create an exception if vstack is somehow pointing to bad memory, but otherwise this is a NOP operation.
We can carry on through the bytecode for every opcode we don't understand and most of them are pretty straightforward, we have some add, or, and mul operations that are fairly simple, let's look at one of these:
vip = &vip[1]
*(vstack - 8) = *(vstack - 8) * *vstack
vstack = vstack - 8
continue
This handler does the following:
- Advances
VIPby one byte - Multiplies the top 2 QWORDS on the stack and puts them 8 bytes (one QWORD) down from the top
- Shifts the stack pointer down by 8 bytes
We can model this in different ways, we can use the 8 byte shifts and offsets, or we can also use some dummy registers and model this using stack operations:
pop rax // get QWORD from top of stack and shift stack back, stack = original-8
pop rdx // get QWORD from top of stack (8 bytes down from original vstack) and shift stack back, stack=original-16
mul rax, rdx // multiply both QWORDS
push rax // put resulting QWORD on stack and advance stack, stack = original-8
There's one other specific VM handler that confused me a bit but is actually kind of nice:
void* rax_100 = &vip[1]
int32_t rax_102 = *rax_100
if (rax_102 == 0)
*(vstack + 8) = &pInputNumber_
else if (rax_102 == 1)
*(vstack + 8) = &pOutputNumber_
vstack = vstack + 8
vip = rax_100 + 4
continue
The function is called with two arguments, and this opcode gets us the address of an argument based on the parameter that is passed as an immediate.
The rest of the handlers are left as an exercise to the reader, let's start converting the bytecode to something readable.
Building the plugin
The API was really enjoyable, with a good amount of documentation (some more examples would be nice), and also easy to test with good errors (standard python) when things went wrong. Here's the basic skeleton of what I built:
from binaryninja import (Architecture, RegisterInfo, InstructionInfo,
InstructionTextToken, InstructionTextTokenType, InstructionTextTokenContext,
BranchType,
LowLevelILOperation, LLIL_TEMP,
LowLevelILLabel,
FlagRole,
LowLevelILFlagCondition,
log_error,
CallingConvention,
interaction,
PluginCommand, BackgroundTaskThread,
HighlightStandardColor
)
import struct
class Tigress1(Architecture):
name = "tigress1"
address_size = 8
default_int_size = 8
max_instr_length = 9
regs = {
"vsp": RegisterInfo("vsp", 8),
"varg1": RegisterInfo("varg1", 8),
"varg2": RegisterInfo("varg2", 8),
"vreg": RegisterInfo("vreg", 8),
"vlhs": RegisterInfo("vlhs", 8),
"vrhs": RegisterInfo("vrhs", 8),
}
stack_pointer = "vsp"
def get_instruction_info(self, data, address):
opcode = data[0]
if opcode == 0x60 or opcode == 0xe1:
# loadq
result = InstructionInfo()
result.length = 9
return result
#elif opcode == 0x4e:
else:
return None
def get_instruction_text(self, data, address):
opcode = data[0]
if opcode == 0x60 or opcode == 0xe1:
# loadq
immediate = struct.unpack("<Q", data[1:9])[0]
tokens = []
tokens.append(InstructionTextToken(InstructionTextTokenType.InstructionToken, "loadq"))
tokens.append(InstructionTextToken(InstructionTextTokenType.OperandSeparatorToken, " "))
tokens.append(InstructionTextToken(InstructionTextTokenType.PossibleAddressToken, hex(immediate), immediate))
return tokens, 9
#elif opcode == 0x4e:
else:
return None
def get_instruction_low_level_il(self, data, address, il):
opcode = data[0]
if opcode == 0x60 or opcode == 0xe1:
# loadq
immediate = struct.unpack("<Q", data[1:9])[0]
il.append(il.push(8, il.const(8, immediate)))
return 9
#elif opcode == 0x4e:
else:
return None
Tigress1.register()
You can take this as-is and dump it in your plugins folder (Tools -> Open Plugin Folder...). You'll need to reload the module if you make any changes, there are plugins to handle this, or you can just close and re-open Binary Ninja to see the changes.
Let's go through what the functions do
get_instruction_info
This is used to tell Binary Ninja the length of an instruction, and if it branches, the type of branch that it does. For most of our instructions we're just going to set the length, and for the jump and return opcodes we'll set the branch details. For example
elif opcode == 0xf4:
# jmp
immediate = struct.unpack("<L", data[1:5])[0]
result = InstructionInfo()
result.length = 5
result.add_branch(BranchType.UnconditionalBranch, address+immediate+1)
return result
get_instruction_text
This is what we'll print out when we look at the disassembly, as well as the length of the opcode we just parsed (as with each of these functions). Most of our opcodes don't take any arguments so we can just print out their name, but with others we'll want to include the parameters and format them correctly. For example
if opcode == 0x60 or opcode == 0xe1:
# loadq
immediate = struct.unpack("<Q", data[1:9])[0]
tokens = []
tokens.append(InstructionTextToken(InstructionTextTokenType.InstructionToken, "loadq"))
tokens.append(InstructionTextToken(InstructionTextTokenType.OperandSeparatorToken, " "))
tokens.append(InstructionTextToken(InstructionTextTokenType.PossibleAddressToken, hex(immediate), immediate))
return tokens, 9
get_instruction_low_level_il
This is where things get really interesting. If we can get this right and lift every command to low level IL then we can let Binary Ninja interpret the code semantically and do a bunch of heavy lifting for us. We get passed an argument il that we can append our operations onto, and we have multiple ways of doing this. For example, we know that this is a stack based virtual machine, and we defined vsp as a register, so we can make use of the push and pop commands in Binary Ninja's LLIL. The first opcode we found, loadq can be implemented fairly simply using this:
if opcode == 0x60 or opcode == 0xe1:
# loadq
immediate = struct.unpack("<Q", data[1:9])[0]
il.append(il.push(8, il.const(8, immediate)))
return 9
We take the immediate and declare it as an 8 byte constant, then use this in an 8 byte push command, and append this to the list of instructions.
Our arithmetic commands are the next obvious ones. We pop two operands, add or multiply them, and push them back on the stack:
elif opcode == 0xc7:
# mulq
product = il.mult(8, il.pop(8), il.pop(8))
il.append(il.push(8, product))
return 1
When we read memory we can pop the address off, load the memory from that location, and then push it back in place:
elif opcode == 0x61 or opcode == 0x6e:
# rmem
il.append(il.push(8, il.load(8, il.pop(8))))
return 1
What happens when the order of instructions is important though, like with a memory write, or a shift or subtraction? There may be other ways of doing this, but I added some dummy registers called lhs and rhs (for the left hand side and right hand side, respectively), and used these to make sure operations were ordered correctly. Then we can construct our other handlers:
elif opcode == 0xdf:
# wmem
il.append(il.set_reg(8, "vlhs", il.pop(8)))
il.append(il.set_reg(8, "vrhs", il.pop(8)))
il.append(il.store(8, il.reg(8, "vlhs"), il.reg(8, "vrhs")))
return 1
elif opcode == 0x42:
# subq
il.append(il.set_reg(8, "vlhs", il.pop(8)))
il.append(il.set_reg(8, "vrhs", il.pop(8)))
sum = il.sub(8, il.reg(8, "vlhs"), il.reg(8, "vrhs"))
il.append(il.push(8, sum))
return 1
It's worth noting that tigress isn't consistent with which order it consumes the stack operands in, so you need to check this with each handler.
Finally, there are the arguments, the return value, and the virtual registers. I implemented the ldarg opcode with each argument as its own register, and we return whatever register corresponds to the offset that is provided. We could also do this with an array of arguments, but the disassembly looks a little nicer this way.
elif opcode == 0x8e:
# ldarg
immediate = struct.unpack("<L", data[1:5])[0]
if immediate == 0:
varg = il.reg(8, "varg1")
elif immediate == 1:
varg = il.reg(8, "varg2")
il.append(il.push(8, varg))
return 5
I've implemented the virtual registers (or scratch space) as an array of QWORDS though, so we just use the parameter as an offset:
elif opcode == 0x90:
# lead
immediate = struct.unpack("<L", data[1:5])[0]
vreg = il.add(8, il.reg(8, "vreg"), il.const(4, immediate))
il.append(il.push(8, vreg))
return 5
And finally, the jump is a relative jump so this is fairly easy to do
lif opcode == 0xf4:
# jmp
immediate = struct.unpack("<L", data[1:5])[0]
dest = immediate + address + 1
il.append(il.jump(il.const(8, dest)))
Reversing the code
Now we have a full architecture plugin for our new VM, let's see how Binary Ninja does at decompiling it:
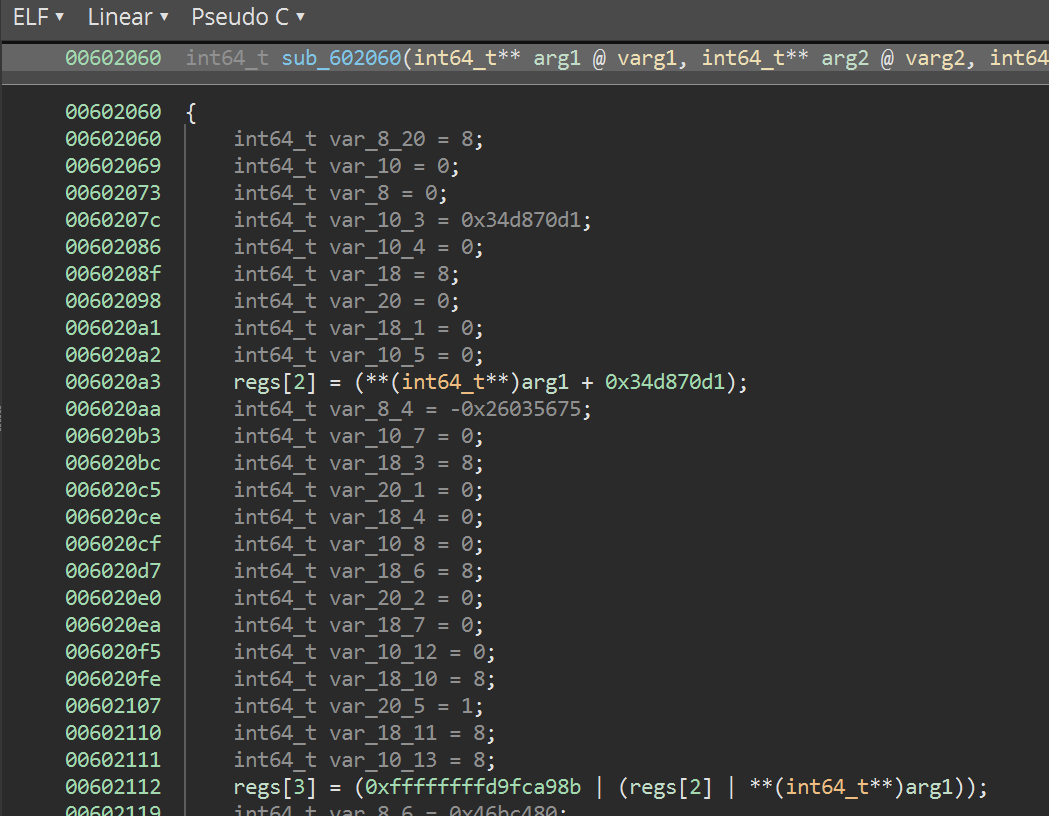
There's a ton of dead-store reduction, and Binary Ninja ends up producing what is basically compilable C code. If we take the whole thing with the dead stores and constant propagation removed, here's what we're left with:
regs[2] = (**(int64_t**)arg1 + 0x34d870d1);
regs[3] = (0xffffffffd9fca98b | (regs[2] | **(int64_t**)arg1));
regs[4] = (0x46bc480 | **(int64_t**)arg1);
regs[5] = (((**(int64_t**)arg1 + 0x1dd9c3c5) << (0x40 - (1 | (0xf & (0x38bca01f * regs[2]))))) | ((**(int64_t**)arg1 + 0x1dd9c3c5) >> (1 | (0xf & (0x38bca01f * regs[2])))));;
regs[5] = (((0x3f & (regs[4] << (1 | (7 & regs[2])))) << 4) | regs[5]);
**(int64_t**)arg2 = (((0x2c7c60b7 * regs[5]) * regs[4]) * (regs[2] + regs[3]));
The only scratch register that gets clobbered is regs[5] but otherwise this is pretty clean, especially for the output we get for free just by building the LLIL parser. We can clean it up a little bit more (for example, the first regs[5] transform is just a bitwise rotation).
Conclusion
This was my first attempt at building a plugin for Binary Ninja, and it was fairly straightforward and easy to work with. It would be nice to have some more code samples (both full hello-world style samples and some more samples in the docs themselves), and some better test harnesses (e.g. easier ways to reload the module without restarting Binary Ninja, or an integration test framework to insert X bytes and see how they do or don't work in the full stack from LLIL to HLIL), but this is definitely a much more accessible and flexible plugin framework than what the other big tools have to offer. Well done Vector35 with this.
Thanks to Amy Burnett for her guide and extension that I used extensively as a reference, and whitequark for her 16bit x86 plugin that was also useful.
The full plugin is at https://github.com/samrussell/tigress_disasm if you want to drop it in and see how it looks.