Reversing LZ91 from Commander Keen
I've been in a bit of a rut with reversing recently and I thought I'd go back to something that I reversed years ago, has a little bit of complexity, but is easy enough that I can focus on extracting one part at a time and getting something turned around in a day or two. I'm going to post the disassembly here, you can follow along at home by getting a copy of Commander Keen yourself (shareware, but also available on any good only game store). For those who are interested in the history of LZ91, take a look at Fabrice Bellard's site.
Let's start from the beginning by opening this up in your favorite disassembler:
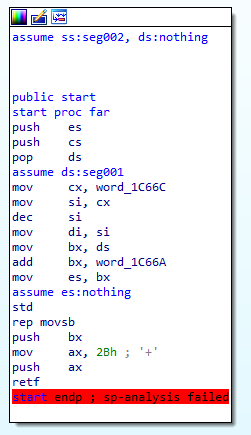
We'll go through instruction by instruction so you can follow along at home. Here's lines 1-3:
push es
push cs
pop ds
We've run into our first problem: what is the value of ES when we start a DOS app? According to OSDev.org, DS and ES both point to the Program Segment Prefix (PSP), a 256 byte (0x100) structure that gets loaded at the bottom of memory, followed directly by the program we've just loaded. We don't need to know much else at this point because you'll notice we never pop this back off the stack.
After this, we push CS and pop it into DS. We do this for two reasons:
- You can't MOV directly between segments
- We want to access some data from the current segment so we need to copy that into DS
So far so good. What's the next big chunk for then?
mov cx, word_1C66C
mov si, cx
dec si
mov di, si
mov bx, ds
add bx, word_1C66A
mov es, bx
std
rep movsb
We see a bunch of things happening here:
- CX gets set (to 0x176)
- This value gets decremented and copied into both SI and DI (SI = DI = 0x175)
- We load DS into BX, add a value (0x0C14) and then put this into ES (ES = DS + 0x0C14)
- We call the STD command and finally do a REP MOVSB
This looks a lot like a memmove command. Normally we copy from the bottom though, like this:
mov cx, 0x176
xor si, si
xor di, di
rep movsb
And at the end both SI and DI point to 0x176, although they last copied a byte to 0x175. Here we're doing this in reverse order. SI and DI start pointing to 0x175, they finish pointing to 0xFFFF, but the final copy is to 0x0000 so we're in the same position.
Why are we doing the copy backwards though? Let's step through manually and it might make sense.
We can assume CS = DS = 0x0000 to make the math easier, and print it like this:
source = 0000:0000; // mem location 0x00000
destination = 0C14:0000; // mem location 0x0C140
count = 0x176;
memmove(destination, source, count);
So we're copying from a low memory location to a higher memory location. The reason we do the copy in reverse is because for a very small file, the memory regions might overlap. We're at the start of the loader so we don't care, but we might override some of the later parts of the loader. Let's try a small example and see what happens:
source = 0x00000
destination = 0x00004
count = 0x10
If we put some junk in memory we can follow this through forwards
// starting case
mem = ABCDEFGHIJKLMNOP0000
// one step
mem = ABCDAFGHIJKLMNOP0000
// two steps
mem = ABCDABGHIJKLMNOP0000
// three steps
mem = ABCDABCHIJKLMNOP0000
// four steps
mem = ABCDABCDIJKLMNOP0000
// five steps
mem = ABCDABCDAJKLMNOP0000
It's broken now! We're now just copying the data that we just copied. If we do this in reverse though:
// starting case
mem = ABCDEFGHIJKLMNOP0000
// one step
mem = ABCDAFGHIJKLMNOP000P
// two steps
mem = ABCDEFGHIJKLMNOP00OP
// three steps
mem = ABCDEFGHIJKLMNOP0NOP
// four steps
mem = ABCDEFGHIJKLMNOPMNOP
// five steps
mem = ABCDEFGHIJKLMNOLMNOP
// ...
// 15 steps
mem = ABCDEBCDEFGHIJKLMNOP
// 16 steps
mem = ABCDABCDEFGHIJKLMNOP
This way we still destroy the data in the middle, but we have a perfect copy at the new destination. It doesn't matter for our analysis why it's done this way, but it's also interesting asking ourselves why things are done a certain way, especially if it relates to code further down the track.
So now we're done with this, what do we have left?
push bx
mov ax, 2Bh ; '+'
push ax
retf
Pushing data before a return is a classic sign of an indirect jump. BX still points to our new segment that we just copied the data to, so we're jumping to ES:002B. We can follow along in our disassembler by just jumping to 002B in the old code because we know it hasn't been overwritten.
Here's where I got to with comments:
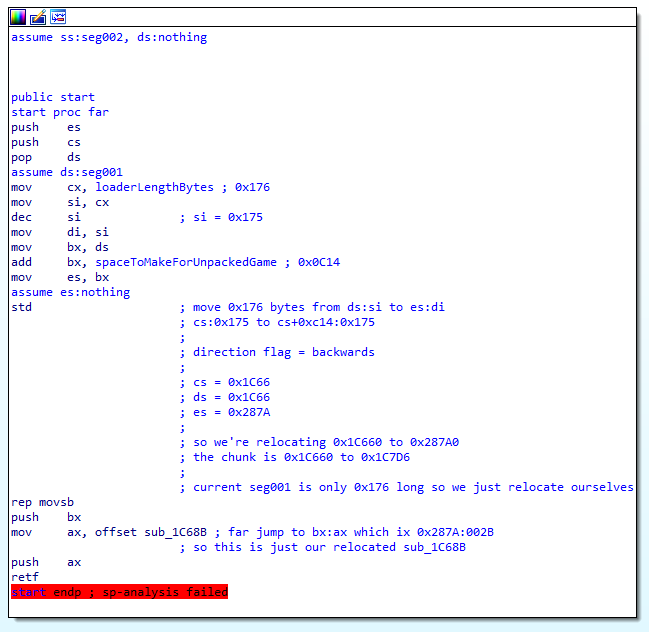
One thing I left out is how we know we're relocating the whole loader... the trick is to look at where our code is. The MZ header loads us at 0C66:000E, and we're copying all of this segment. When we jump to the next function we can see it only goes to 0C66:0176 (including the data on the end). Not the best explanation, I know, and if this doesn't make sense then take a closer look in your own disassembly to see where we got this number from.
Anyway, let's look at function number 2 here:
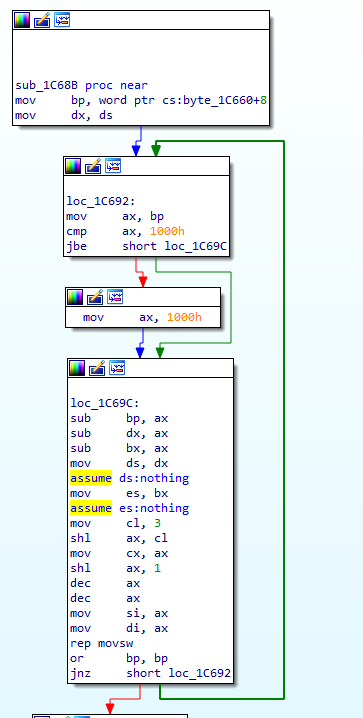
This is going to be fun. Let's start from the top and see if we can make sense of it as we go:
mov bp, word ptr cs:byte_1C660+8
mov dx, ds
If we tidy this up we can see it loads 0x0C66 into BP, and loads DS into DX. We know that 0x0C66 is our original CS (but not relocated, this is important). We also haven't touched DS since our memmove so we know that this is the CS that we got loaded to (this has been relocated). In other words, BP = 0x0C66, DX = 0x0C66 + relocation_offset.
We then hit the start of a loop:
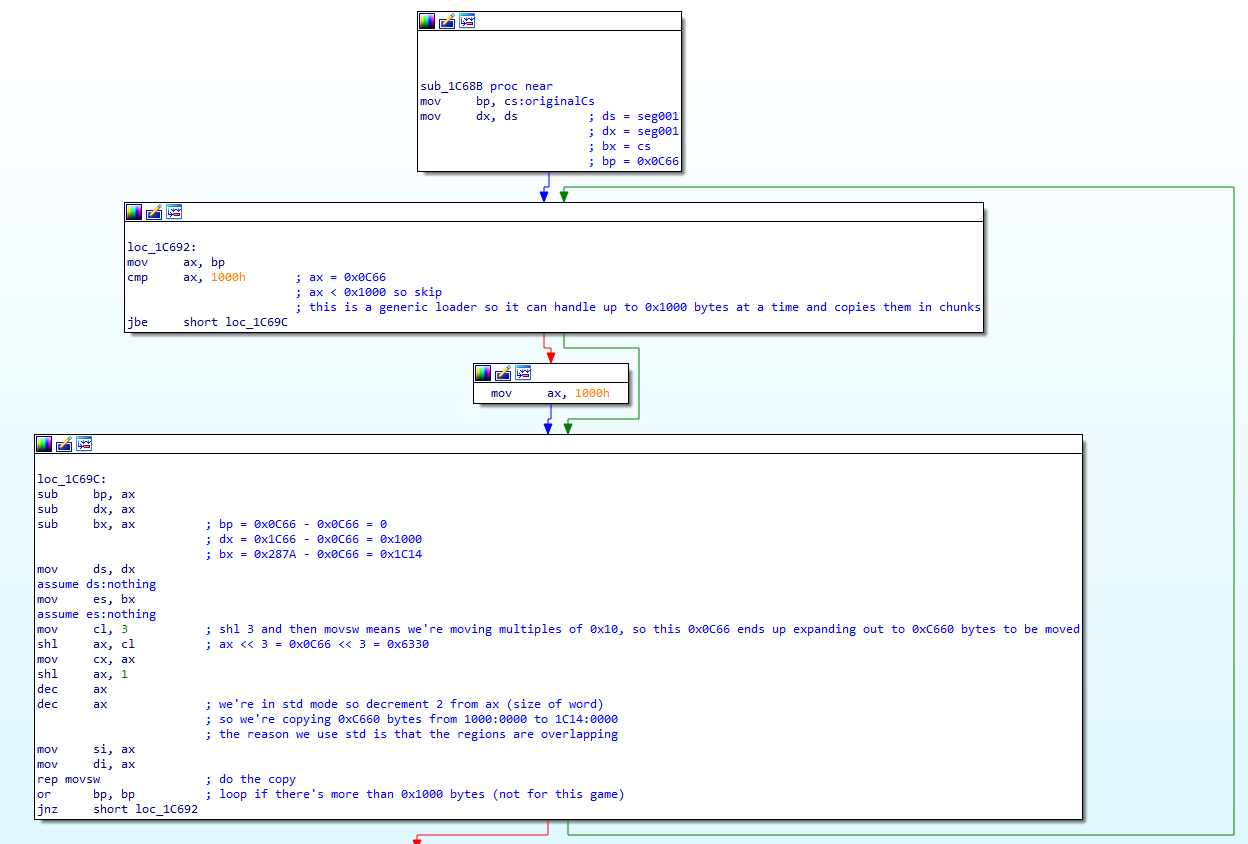
loc_1C692:
mov ax, bp
cmp ax, 1000h
jbe short loc_1C69C
BP is our original un-relocated CS, and it looks like our loader gets loaded at the end of the packed data. In other words, this could also be the size in paragraphs (0x10 byte chunks, what the segment register operates in) of our packed data. We compare it to 0x1000, and if it's greater, then:
mov ax, 1000h
So this does seem like a counter that goes in chunks of 0x1000 at a time. The next chunk is where the magic happens:
loc_1C69C:
sub bp, ax
sub dx, ax
sub bx, ax
If BP is the total we were meant to do then this lines up with our theory - we do this in chunks of up to 0x1000 at a time and here we're reducing BP (our counter for total amount of work to do), DX (our original CS), and BX (the segment that we relocated the loader to). We just relocated the loader further up in memory, and it looks like we might be about to do the same with the packed code:
mov ds, dx
mov es, bx
The MOVS commands go from DS:SI to ES:DI, so it does appear that we're just moving the packed code up to line up with our loader (now that we've jumpeed up here we can overwrite ourselves)
mov cl, 3
shl ax, cl
This seems odd. We're setting CX to AX 8. We would expect it to be AX 0x10 if we were doing MOVSB (since we know that AX is a number of paragraphs to copy, or multiples of 0x10). If we look further down we see a REP MOVSW, and 0x10 bytes is the same as 8 words, so this does seem to line up correctly.
mov cx, ax
shl ax, 1
dec ax
dec ax
mov si, ax
mov di, ax
rep movsw
This is the same pattern we saw before, but we need to decrement AX twice because our offsets are going in 2's because we're moving words, not bytes. This is also why we had to decrement our segments, because we need our offsets to start high and drop all the way down to 0.
or bp, bp
jnz short loc_1C692
And this is the bottom of the loop - if we had more than 0x1000 paragraphs to copy then go back and do the next chunk. For Commander Keen we only have 0x0C66 so we only run through this loop once.
Here are my notes so far:
One thing to keep in mind - none of this relocation matters for us when we write our unpacker because we're just reading from disk.
Anyway, next part:
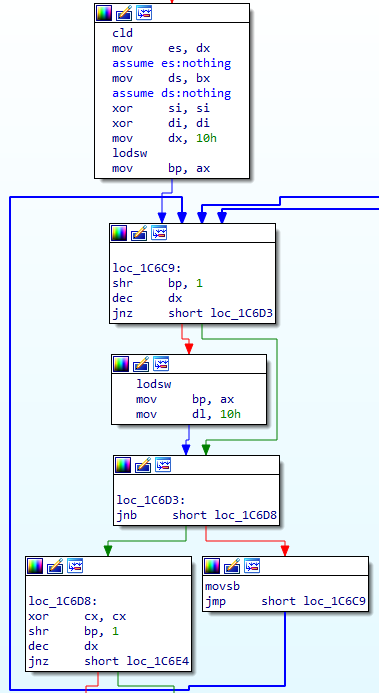
We start with this:
cld
This sets the direction to forwards, so our MOVS/LODS/STOS commands move SI/DI forwards instead of backwards.
mov es, dx
mov ds, bx
xor si, si
xor di, di
We're swapping our segments around, we were copying from low to high, and now we're copying from high to low. Looks like we're going to start overwriting our original packed code with unpacked code as we go along. We've also cleared out SI and DI so we are definitely starting from the beginning.
mov dx, 10h
lodsw
mov bp, ax
We've loaded a word into BP and set DX to 0x10. I wonder what this means?
loc_1C6C9:
shr bp, 1
dec dx
jnz short loc_1C6D3
Oh this makes sense - BP holds 16 bits, and we can shift them out one at a time. Here we've shifted a bit out of BP, and then decremented DX. If DX isn't zero then we skip the next bit, but if it DX is zero then we've run out of bits and:
lodsw
mov bp, ax
mov dl, 10h
We fill up again and reset DL (we know DH is 0).
loc_1C6D3:
jnb short loc_1C6D8
This is weird. What does JNB do? It turns out this jumps if CF is 0, and what sets the CF? Normally we expect arithmetic to set/clear all the flags, but it the DEC command doesn't set CF (it sets others though, like OF and ZF). That means we're testing the result of the SHR command earlier - we're checking if the bit we shifted out was 0. If it was 1 (CF = 1 so the JNB fails) then we do this:
movsb
jmp short loc_1C6C9
And we copy a byte across uncompressed, and loop back to the top.
From what we know about LZ style compression, we normally copy across the first few bytes uncompressed and then start to get the benefits of our compression as we unpack more and more. Because of this, we'd expect the first few bytes to be uncompressed. Let's take a look at what the data shows, right at the start of the file after the header:

Just as we thought: the first word that gets loaded is 0xFFFF (16x 1 bit), so it copies across 16 bytes uncompressed. Note that we see 15 uncompressed bytes and then 0xFFFF, this is because we refresh our bits the moment they run out (after the 16th bit), we don't wait until after the operation is done.
Here are the notes so far:
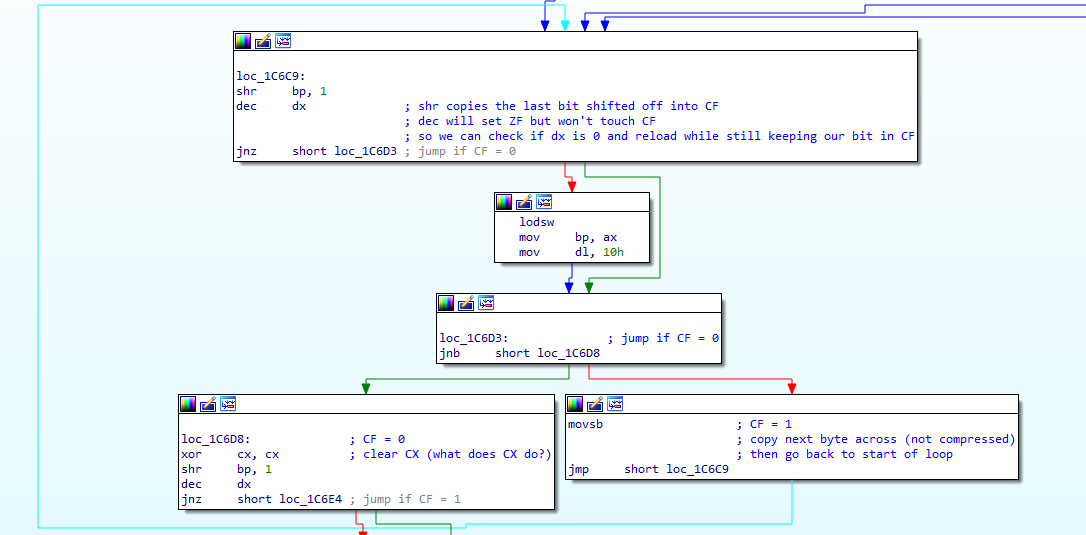
So if we get a 1 bit then we copy a byte across, but what happens if we get a 0 bit?
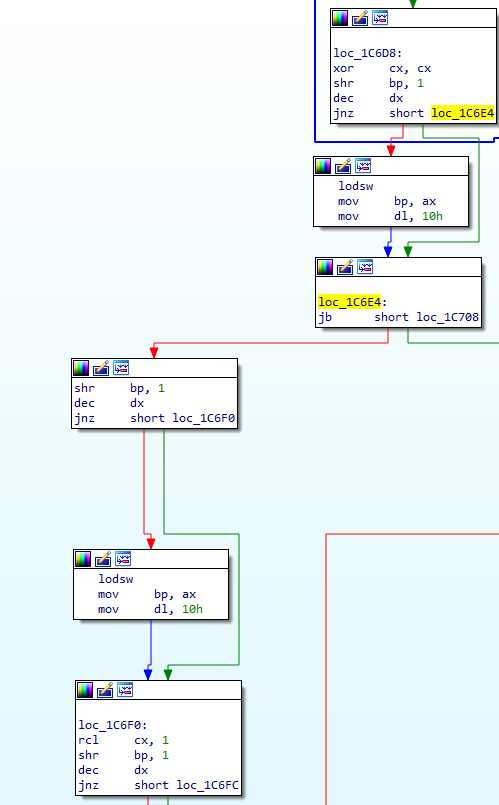
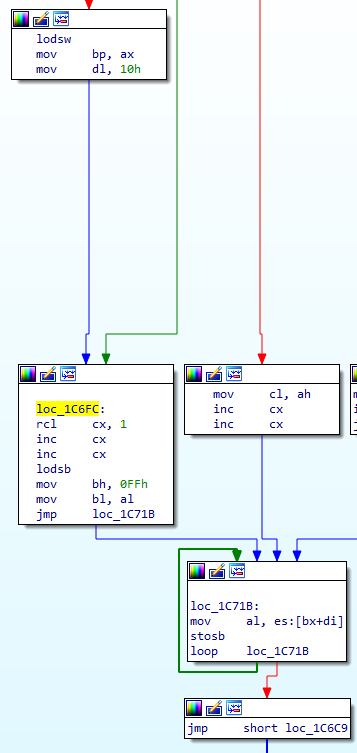
loc_1C6D8:
xor cx, cx
shr bp, 1
dec dx
jnz short loc_1C6E4
lodsw
mov bp, ax
mov dl, 10h
loc_1C6E4:
jb short loc_1C708
We clear CX and get another bit. We refill if needed (this happens every time so this is the last time I'll show this refill part), and if CF is set then we jump right. We'll handle that next, first off, let's handle the CF=0 case (so when we get 00 bits).
shr bp, 1
; refill if needed
rcl cx, 1
shr bp, 1
; refill if needed
rcl cx, 1
inc cx
inc cx
We set CX to 0 earlier, and the RCL command rotates in bits from the CF, letting us stack these up on the bottom. We basically copy the next 2 bits from BP into CX, then add 2 from here. This set CX to a number from 2-5 based on our bits in BP.
lodsb
mov bh, 0FFh
mov bl, al
jmp loc_1C71B
We then load in another byte, sign extend it to a word (top bit is 1 so it's a negative number)
loc_1C71B:
mov al, es:[bx+di]
stosb
loop loc_1C71B
We then load in a byte from our output data, and then put it back on the end, and increment di. We know bx is going to be a negative number, and CX is a number from 2-5 so this code is copying a 2-5 byte chunk from the uncompressed code and sticking it on the front. This is standard for LZ-style compression.
So we now know what the following sets of bits do:
- 1: copy byte across
- 00: copy 2-5 bytes from up to 255 bytes back in uncompressed
Let's carry on with that right hand branch we skipped earlier:
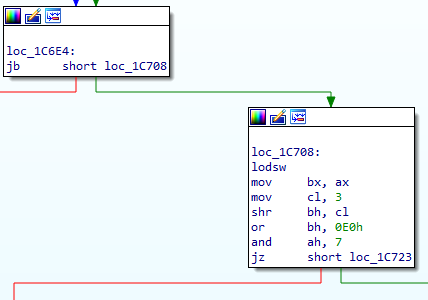
This looks insane. This is the sort of thing that makes you want to just give up and cry. I'll let you cheat on this one and jump straight to my notes:
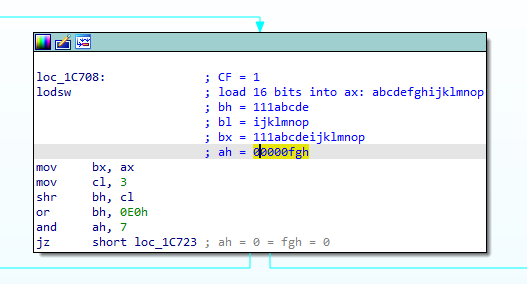
We load another 2 bytes and we do some weird arithmetic with it. BX gets 13 of the bits and then gets sign extended, allowing us to look up to 0x2000 bytes back. AH gets 3 bits (from the middle, for some reason), and we check if these are zero. If they aren't, then we skip the jump and get to this:
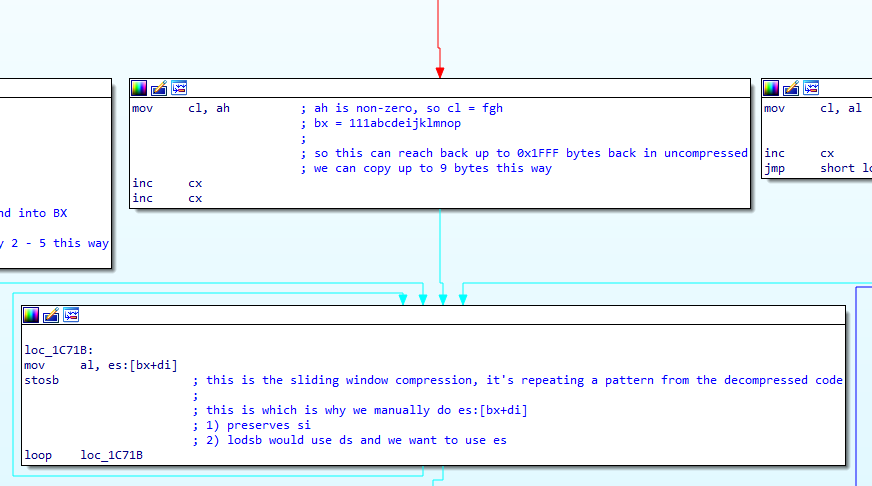
We add 2 to our AH and put it in CL. We can add to our list of branches:
- 1: copy byte across
- 00: copy 2-5 bytes from up to 255 bytes back in uncompressed
- 01, next word != XXXXX000XXXXXXXXb, copy 2-9 bytes from up to 8192 bytes back in uncompressed
Now the next branch, what happens when AH is 0?
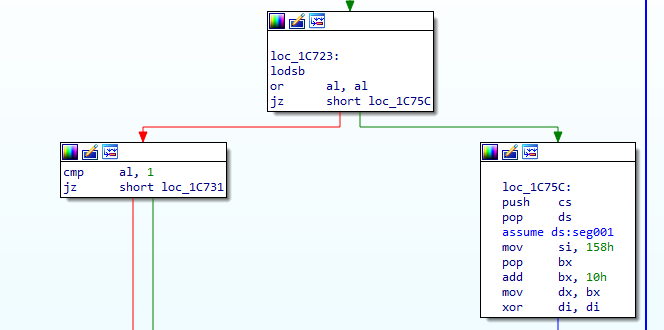
We get another byte. If that byte is 0 then we jump to another branch that doesn't loop back, that's our exit code.
- 1: copy byte across
- 00: copy 2-5 bytes from up to 255 bytes back in uncompressed
- 01, next word != XXXXX000XXXXXXXXb, copy 2-9 bytes from up to 8192 bytes back in uncompressed
- 01, next word == XXXXX000XXXXXXXXb, next byte == 0, break
What about when our next byte is 1? This is a fun one:

mov bx, di
and di, 0Fh
add di, 2000h
We know DI is our offset pointer for uncompressed data. Here we're saving it in BX, taking just the bottom nybble (masking against 0x0F) and then adding 0x2000.
mov cl, 4
shr bx, cl
mov ax, es
add ax, bx
sub ax, 200h
mov es, ax
And here's the other half, we scale BX down by 4 bits (so it would make a good segment register), add ES, then subtract 0x200, and finally put it all back in ES.
It looks we're resetting DI and bumping ES forward to compensate, this is something we'd do when we're getting to the end of the segment. For example, if we get to 0000:E123, we'd want to make sure we have more room to write to, so we can easily rewrite this as 0E12:0003.
BUT... when we decompress we can look up to 0x2000 bytes backward, so we probably want DI to be at least 0x2000. We can rephrase 0E12:0003 and 0C12:2003, this gives us more room to grow upward, but also lets us reach back to decompress.
mov bx, si
and si, 0Fh
shr bx, cl
mov ax, ds
add ax, bx
mov ds, ax
jmp loc_1C6C9
This is exactly the same thing but with DS:SI. Note that this doesn't get called all the time, only when the compressed code tells us to. That saves on CPU cycles while only costing a few bytes per 3-4KB of packed data, not bad at all.
- 1: copy byte across
- 00: copy 2-5 bytes from up to 255 bytes back in uncompressed
- 01, next word != XXXXX000XXXXXXXXb, copy 2-9 bytes from up to 8192 bytes back in uncompressed
- 01, next word == XXXXX000XXXXXXXXb, next byte == 0, break
- 01, next word == XXXXX000XXXXXXXXb, next byte == 1, rephrase segment/offset pairs
We have one final case and then we're done!
mov cl, al
inc cx
jmp short loc_1C71B
If next byte is 2 or higher then we increment it and use our large BX to look back, letting us copy up to 0x100 bytes:
- 1: copy byte across
- 00: copy 2-5 bytes from up to 255 bytes back in uncompressed
- 01, next word != XXXXX000XXXXXXXXb, copy 2-9 bytes from up to 8192 bytes back in uncompressed
- 01, next word == XXXXX000XXXXXXXXb, next byte == 0, break
- 01, next word == XXXXX000XXXXXXXXb, next byte == 1, rephrase segment/offset pairs
- 01, next word == XXXXX000XXXXXXXXb, next byte == 2, copy 3-256 bytes from up to 8192 bytes back in uncompressed
And we're done with the decompression! I've rewritten this in python as an unpacker, here's how it looks:
while True:
bit = bitstream.get()
if bit == 1:
byte, = input_stream.read(1)
output_stream.write(bytes([byte]))
else:
bit = bitstream.get()
if bit == 1:
lowbyte, highbyte = input_stream.read(2)
copy_distance = 0xE000 | ((highbyte << 5) & 0xFF00) | lowbyte
copy_distance = convert_unsigned_to_signed(copy_distance, 0x10)
copy_amount = highbyte & 0x07
if copy_amount:
copy_amount += 2
copy_within_output_stream(output_stream, copy_distance, copy_amount)
else:
copy_amount, = input_stream.read(1)
if copy_amount == 0:
break
elif copy_amount == 1:
# segment reshuffle, ignore
pass
else:
copy_amount += 1
copy_within_output_stream(output_stream, copy_distance, copy_amount)
else:
high_bit = bitstream.get()
low_bit = bitstream.get()
copy_amount = (high_bit << 1) + low_bit + 2
copy_distance, = input_stream.read(1)
copy_distance = convert_unsigned_to_signed(0xFF00 + copy_distance, 0x10)
copy_within_output_stream(output_stream, copy_distance, copy_amount)
Nice and easy. Let's look at where the break takes us at the end:
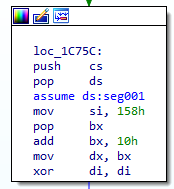
push cs
pop ds
We're done with the code, now we're looking at data from this segment
mov si, 158h
That's pretty weird. DS is in this segment though, so what does DS:158 look like?
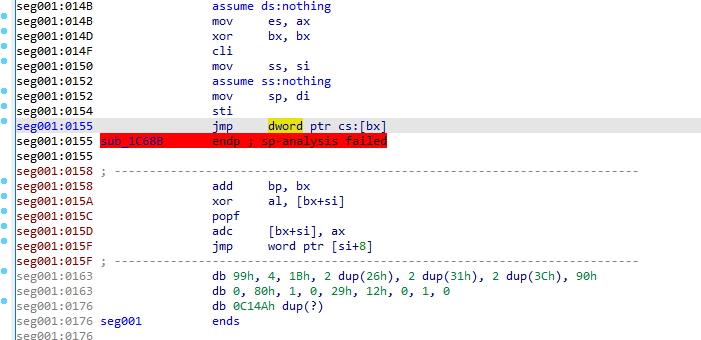
Ahhhh, so we're pulling data out from after the end of the loader. Let's see what we do with it:
pop bx
add bx, 10h
We haven't seen the stack in a while, have we? Right at the start we pushed ES and I said two things about ES:
- It points to the PSP segment
- The PSP is 0x100 bytes long, or in other words, CS is 0x10 bytes greater
So we're reconstructing the original CS that we got loaded into based on the ES that we pushed at the start.
mov dx, bx
xor di, di
DX stores old CS? DI holds 0? What could be coming? We have some branches coming up so let's see what happens:
loc_1C769:
lodsb
or al, al
jz short loc_1C784
We load a byte and jump if it's zero. Let's see what happens when it isn't zero:
mov ah, 0
loc_1C770:
add di, ax
We set DI to 0 at the start, so we're advancing DI by up to 0xFF (from the byte we loaded)
mov ax, di
and di, 0Fh
We save DI in AX, and just keep the bottom nybble
mov cl, 4
shr ax, cl
We shift AX down, this looks like something we'd add to a segment register
add dx, ax
mov es, dx
DX was our old CS from above, so we've added our new offset and store it in ES. In other words, we had DX:DI = CS:0000, we added a byte (let's say 0C66:0028), we stole the high bits from DI and put them into DX (e.g. 0C68:0008), then we put DX into ES.
add es:[di], bx
jmp short loc_1C769
BX still points to our original CS, and we're adding it to a value at ES:DI. This looks like what we'd do if we were applying relocations... and an EXE would have a relocation table that would need to be applied once we unpacked the EXE...
So we have branch 1:
- byte > 0: advance DX:DI and apply relocation
The next branch, when the byte == 0:
loc_1C784:
lodsw
or ax, ax
jnz short loc_1C791
We load a word, what happens if it's 0?
add dx, 0FFFh
mov es, dx
jmp short loc_1C769
We advance DX by a lot (0xFFF) and go back to the start.
- byte > 0: advance DX:DI and apply relocation
- byte == 0 and next word == 0: advance DX by 0xFFF
What about when the word is >1?
loc_1C791:
cmp ax, 1
jnz short loc_1C770
loc_1C770:
...
We've been here before, but we're advancing by a whole word, not just a byte.
- byte > 0: advance DX:DI and apply relocation
- byte == 0 and next word == 0: advance DX by 0xFFF
- byte == 0 and next word > 1: advance DX:DI and apply relocation
And the last case is the end, so we'll hit this once we've applied all the relocations. Before we do this though, let's look at how the python for this works, given we aren't trying apply relocations, but rather we want to rebuild the relocation table for the new EXE we're going to make:
while True:
first_byte, = input_stream.read(1)
if first_byte > 0:
relocation += first_byte
relocations.append(relocation)
else:
lowbyte, highbyte = input_stream.read(2)
total = (highbyte << 0x08) + lowbyte
if total == 0:
relocation += 0xFFF
elif total == 1:
break
else:
relocation += total
relocations.append(relocation)
Now we can break apart the final section:
mov ax, bx
This is the CS that we got loaded to, now stored in AX
mov di, word ptr unk_1C664
mov si, word ptr unk_1C666
add si, ax
We can see further down that these get loaded into SS:SP so we can rename these vars accordingly. We relocate SI (the new SS) by CS to bump it up
add word ptr unk_1C662, ax
This var looks like a segment register
sub ax, 10h
mov ds, ax
mov es, ax
AX now points to the PSP and we load this into DS and ES
xor bx, bx
BX = 0...
cli
mov ss, si
mov sp, di
sti
Nice to stop interrupts while we're messing with the stack
jmp dword ptr cs:[bx]
We're jumping to the far pointer at CS:0000. What's there?

Ahhhhh, so this is the original CS:IP that the packed EXE goes into (which is why we had to relocate the segment stored there). Full notes:
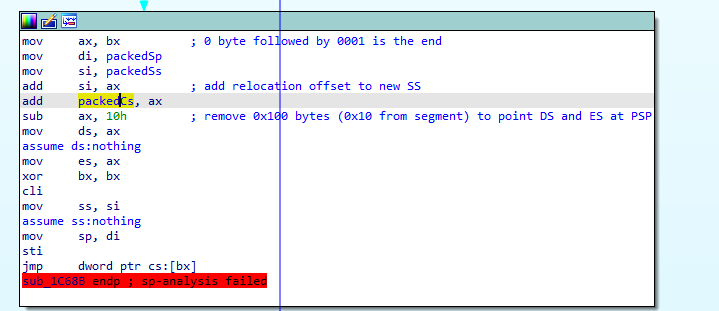
This was a lot of fun to reverse, fun to write up, and also quite enjoyable putting an unpacker together. You can find the unpacker here, it'll give you a decompressed copy of commander keen and rebuild the EXE header + relocations for you.
Happy reversing dudes